pteletronica
O isolador USB salvou meu notebook de um inversor em chamas
Fabio 03 Aug 2026 segurança, inversores, e proteçãoCá estava eu em mais um dia comum programando um inversor para motores. O sistema estava rodando um motor de 1,5 CV a aproximadamente 30 Hz quando algo começou a parecer estranho. O giro ficou irregular, o motor começou a desbalancear e, de repente, aconteceu.
A placa começou a soltar raios, fogo e pequenas explosões. As luzes se apagaram, flashes e estouros ficaram altos e assustadores. Foi aquele momento em que você não sabe se corre ou se fica olhando, tentando entender se ainda há algo a salvar. Os disjuntores da rede caíram, mas ainda havia fogo e algumas explosões ocasionais vindas dos dois capacitores de 1000 µF a 350 V descarregando sabe-se lá em quem.
 |
Placa pegando fogo no escuro porque o disjuntor da luz também caiu. |
Passado o susto inicial, com a luz restabelecida, apaguei uma pequena chama que insistia no isolamento de alguns fios. O cenário não era bonito: placa carbonizada, microcontrolador explodido, pinos de gravação simplesmente não existiam mais. Cheiro de borracha queimada no ar, fios grudados uns nos outros e aquele silêncio estranho depois da confusão.
Olhei rapidamente para o lado, já imaginando o pior. Naquele instante pensei em todos os dados, nos projetos, no prejuízo de ter que comprar outro computador — especialmente em tempos em que notebooks estão cada vez mais caros.
Mas então percebi algo inesperado.
Tela funcionando.
VSCode aberto.
Nenhum sinal de dano.
A única reação do notebook parecia ser o ventilador acelerando um pouco por causa do calor do momento.
Foi então que olhei para a esquerda e vi o pequeno dispositivo que provavelmente havia evitado um desastre maior: um simples isolador USB entre o computador e o programador.

Naquele momento ficou claro que ele havia feito exatamente o trabalho para o qual foi projetado.
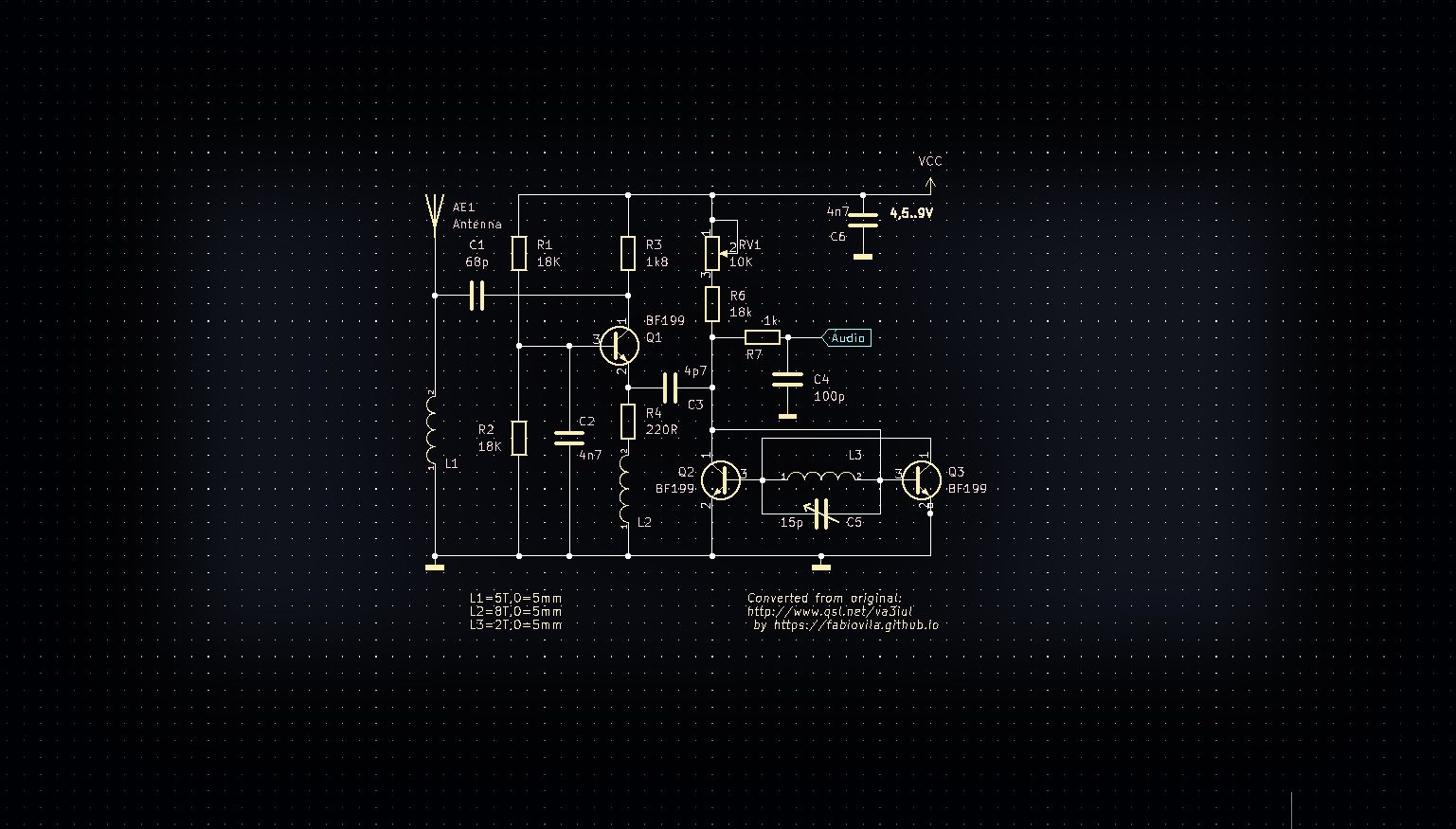
Quando comecei a trabalhar com inversores, eu já tinha consciência de que algo assim poderia acontecer. Em muitas placas de potência o microcontrolador compartilha o mesmo GND do módulo de potência, sem nenhuma isolação real.
Isso significa que o computador conectado via USB acaba, na prática, ligado eletricamente ao circuito de potência.
Em inversores alimentados por rede retificada, o barramento DC pode facilmente chegar a cerca de 310 V. Qualquer falha, transiente ou desbalanceamento entre os referenciais de terra pode colocar tensões perigosas no caminho entre a placa e o computador.
Na prática, isso pode transformar o cabo USB em um caminho inesperado para correntes de falha.
Era até relativamente comum eu levar pequenos choques ao tocar na parte metálica do conector USB enquanto fazia testes. Na época eu ignorava, mas aquilo já era um sinal claro de que algo não estava exatamente saudável no sistema.
Algum tempo atrás, navegando sem grandes pretensões pelo Aliexpress, encontrei pequenos isoladores USB usados normalmente em aplicações de áudio.

Eles eram baratos e prometiam algo interessante: isolamento galvânico entre o computador e o dispositivo USB.
Resolvi testar.
E funcionou.
Esses isoladores utilizam normalmente o chip ADuM3160, da Analog Devices, projetado especificamente para isolamento de comunicação USB. Internamente ele usa acoplamento magnético para transferir os sinais digitais através de uma barreira de isolamento, quebrando o caminho elétrico direto entre os dois lados do sistema.
Isso significa que o computador e o circuito conectado deixam de compartilhar o mesmo caminho de corrente.
Em outras palavras: mesmo que algo terrível aconteça no circuito de potência, a chance de essa energia chegar ao computador cai drasticamente.
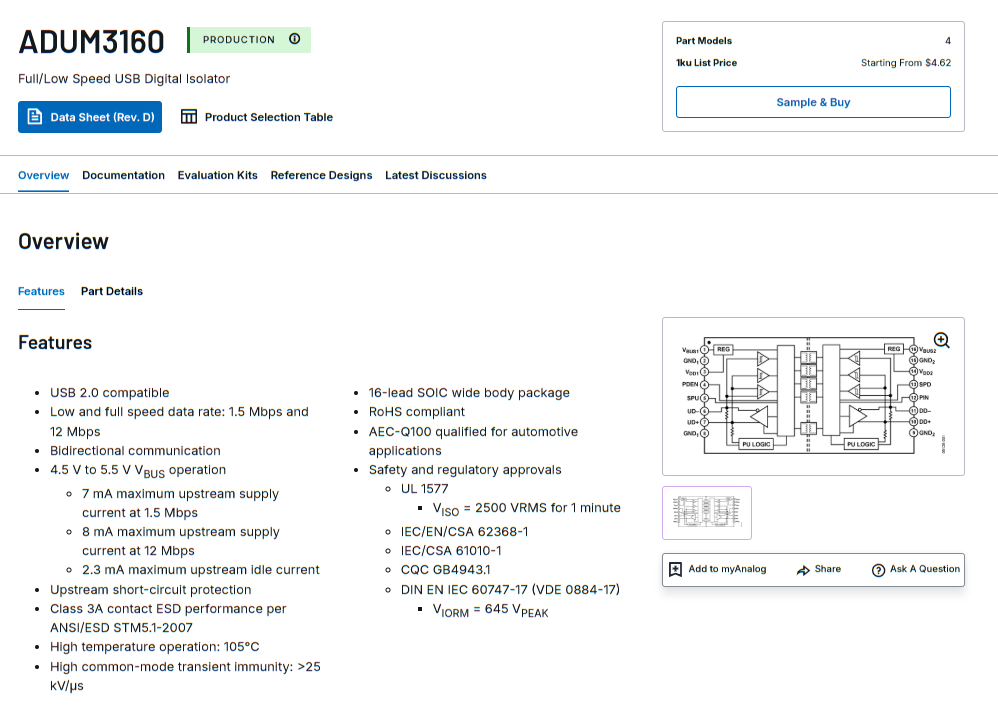
Esses dispositivos não são perfeitos.
Embora suportem conexão USB 2.0, na prática a velocidade fica limitada ao equivalente ao USB 1.1. Para a maioria das aplicações industriais ou de laboratório isso não é um grande problema.
No meu caso, utilizando conversores USB-serial, consegui comunicação estável até 576000 baud, o que é mais do que suficiente para debug e telemetria de firmware.
Para gravação de microcontroladores e comunicação serial comum, a limitação de velocidade praticamente não incomoda.
Depois daquele episódio ficou uma lição simples:
Debuggar inversores conectando diretamente o computador ao circuito de potência não é uma boa ideia.
Um isolador USB custa poucos dólares.
Um notebook custa alguns milhares.
Naquele dia, entre uma placa carbonizada e um computador intacto, ficou claro qual dos dois vale mais a pena proteger.
MAIS ARTIGOS